2026

Scale-Aware Self-Supervised Learning for Segmentation of Small and Sparse Structures
Jorge Quesada, Ghassan AlRegib
International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2026
We propose a scale-aware SSL strategy that zooms in on small-window crops during pretraining to better capture fine-grained patterns. This approach aligns representation learning with the intrinsic scale of sparse structures, significantly improving the segmentation of seismic faults and cellular targets.
Scale-Aware Self-Supervised Learning for Segmentation of Small and Sparse Structures
Jorge Quesada, Ghassan AlRegib
International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2026
We propose a scale-aware SSL strategy that zooms in on small-window crops during pretraining to better capture fine-grained patterns. This approach aligns representation learning with the intrinsic scale of sparse structures, significantly improving the segmentation of seismic faults and cellular targets.
2025
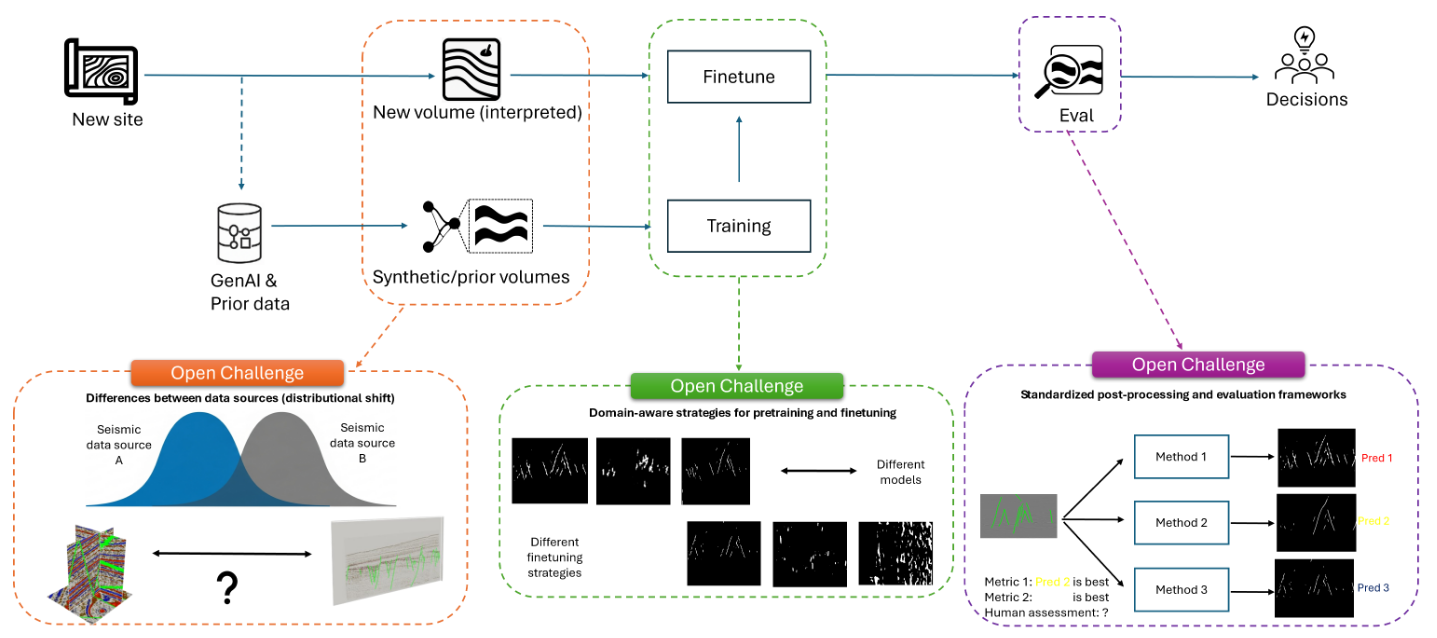
A Large-scale Benchmark on Geological Fault Delineation Models: Domain Shift, Training Dynamics, Generalizability, Evaluation and Inferential Behavior
Jorge Quesada, Chen Zhou, Prithwijit Chowdhury, Mohammad Alotaibi, Ahmad Mustafa, Yusuf Kumakov, Mohit Prabhushankar, Ghassan AlRegib
IEEE Access 2025
We present the first large-scale benchmarking study for geological fault delineation. The benchmark evaluates over 200 model–dataset–strategy combinations under varying domain shift conditions, providing new insights into generalizability, training dynamics, and evaluation practices in seismic interpretation.
A Large-scale Benchmark on Geological Fault Delineation Models: Domain Shift, Training Dynamics, Generalizability, Evaluation and Inferential Behavior
Jorge Quesada, Chen Zhou, Prithwijit Chowdhury, Mohammad Alotaibi, Ahmad Mustafa, Yusuf Kumakov, Mohit Prabhushankar, Ghassan AlRegib
IEEE Access 2025
We present the first large-scale benchmarking study for geological fault delineation. The benchmark evaluates over 200 model–dataset–strategy combinations under varying domain shift conditions, providing new insights into generalizability, training dynamics, and evaluation practices in seismic interpretation.
2024
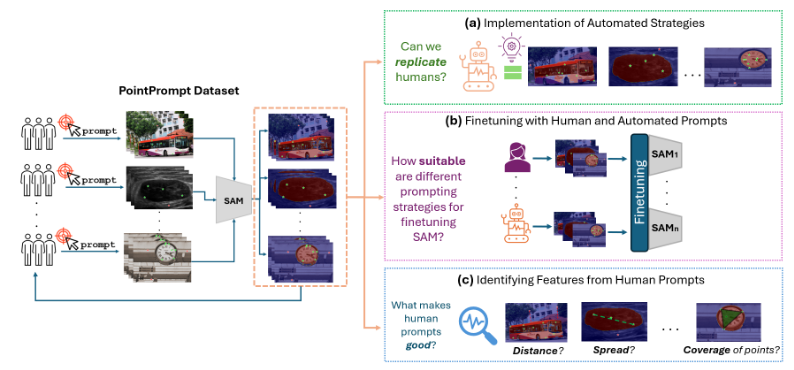
Benchmarking Human and Automated Prompting in the Segment Anything Model
Jorge Quesada*, Zoe Fowler*, Mohammad Alotaibi, Mohit Prabhushankar, Ghassan AlRegib (* equal contribution)
IEEE International Conference on Big Data 2024
We compare human-driven and automated prompting strategies in the Segment Anything Model (SAM). Through large-scale benchmarking, we identify prompting patterns that maximize segmentation accuracy across diverse visual domains.
Benchmarking Human and Automated Prompting in the Segment Anything Model
Jorge Quesada*, Zoe Fowler*, Mohammad Alotaibi, Mohit Prabhushankar, Ghassan AlRegib (* equal contribution)
IEEE International Conference on Big Data 2024
We compare human-driven and automated prompting strategies in the Segment Anything Model (SAM). Through large-scale benchmarking, we identify prompting patterns that maximize segmentation accuracy across diverse visual domains.
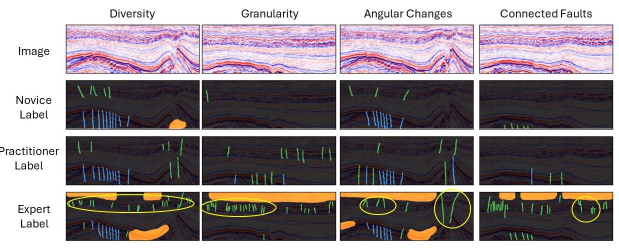
CRACKS: Crowdsourcing Resources for Analysis and Categorization of Key Subsurface faults
Mohit Prabhushankar, Kiran Kokilepersaud*, Jorge Quesada*, Yavuz Yarici*, Chen Zhou, Mohammad Alotaibi, Ghassan AlRegib, Ahmad Mustafa, Yusufjon Kumakov (* equal contribution)
Under review.
In this work, we develop a dataset with annotations of seismic faults across different levels of annotator expertise.
CRACKS: Crowdsourcing Resources for Analysis and Categorization of Key Subsurface faults
Mohit Prabhushankar, Kiran Kokilepersaud*, Jorge Quesada*, Yavuz Yarici*, Chen Zhou, Mohammad Alotaibi, Ghassan AlRegib, Ahmad Mustafa, Yusufjon Kumakov (* equal contribution)
Under review.
In this work, we develop a dataset with annotations of seismic faults across different levels of annotator expertise.
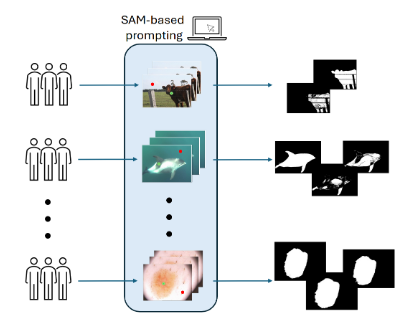
PointPrompt: A Multi-modal Prompting Dataset for Segment Anything Model
Jorge Quesada, Mohammad Alotaibi, Mohit Prabhushankar, Ghassan AlRegib
Conference on Computer Vision and Pattern Recognition (CVPR) Workshop on Prompting in Vision 2024
We introduce PointPrompt, a multi-modal prompting dataset designed for evaluating and advancing the Segment Anything Model (SAM). PointPrompt facilitates systematic benchmarking of prompt-driven segmentation across diverse domains.
PointPrompt: A Multi-modal Prompting Dataset for Segment Anything Model
Jorge Quesada, Mohammad Alotaibi, Mohit Prabhushankar, Ghassan AlRegib
Conference on Computer Vision and Pattern Recognition (CVPR) Workshop on Prompting in Vision 2024
We introduce PointPrompt, a multi-modal prompting dataset designed for evaluating and advancing the Segment Anything Model (SAM). PointPrompt facilitates systematic benchmarking of prompt-driven segmentation across diverse domains.
2022

MTNeuro: A Benchmark for Evaluating Representations of Brain Structure Across Multiple Levels of Abstraction
Jorge Quesada, Lakshmi Sathidevi, Ran Liu, Nauman Ahad, Joy M. Jackson, Mehdi Azabou, Christopher Liding, Matthew Jin, Carolina Urzay, William Gray-Roncal, Erik Johnson, Eva Dyer
NeurIPS Datasets and Benchmarks Track 2022
We introduce MTNeuro, a multi-task neuroimaging benchmark built on volumetric, micrometer-resolution X-ray microtomography of mouse thalamocortical regions. The benchmark spans diverse prediction tasks—including brain-region classification and microstructure segmentation—and offers insights into the representation capabilities of supervised and self-supervised models across multiple abstraction levels.
MTNeuro: A Benchmark for Evaluating Representations of Brain Structure Across Multiple Levels of Abstraction
Jorge Quesada, Lakshmi Sathidevi, Ran Liu, Nauman Ahad, Joy M. Jackson, Mehdi Azabou, Christopher Liding, Matthew Jin, Carolina Urzay, William Gray-Roncal, Erik Johnson, Eva Dyer
NeurIPS Datasets and Benchmarks Track 2022
We introduce MTNeuro, a multi-task neuroimaging benchmark built on volumetric, micrometer-resolution X-ray microtomography of mouse thalamocortical regions. The benchmark spans diverse prediction tasks—including brain-region classification and microstructure segmentation—and offers insights into the representation capabilities of supervised and self-supervised models across multiple abstraction levels.
2019
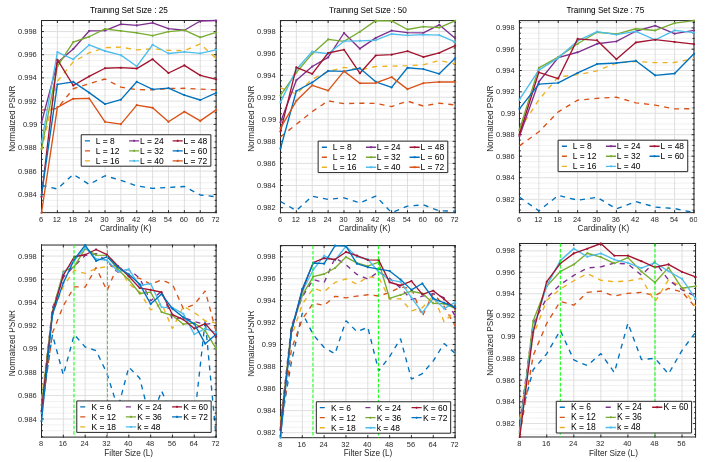
Hyper-parameter Selection on Convolutional Dictionary Learning Through Local ℓ0,∞ Norm
Gustavo Silva, Jorge Quesada, Paul Rodríguez
European Signal Processing Conference (EUSIPCO) 2019
We empirically study how filter size and dictionary cardinality affect convolutional dictionary learning, showing the local ℓ0,∞ sparsity measure correlates with denoising PSNR and suggesting practical lower bounds.
Hyper-parameter Selection on Convolutional Dictionary Learning Through Local ℓ0,∞ Norm
Gustavo Silva, Jorge Quesada, Paul Rodríguez
European Signal Processing Conference (EUSIPCO) 2019
We empirically study how filter size and dictionary cardinality affect convolutional dictionary learning, showing the local ℓ0,∞ sparsity measure correlates with denoising PSNR and suggesting practical lower bounds.
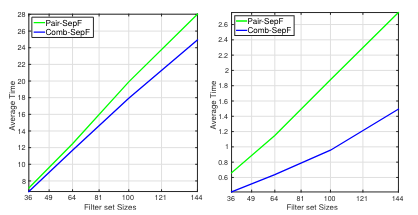
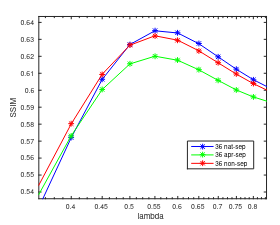
Combinatorial Separable Convolutional Dictionaries
Jorge Quesada, Gustavo Silva, Paul Rodríguez, Brendt Wohlberg
IEEE Symposium on Image, Signal Processing and Artificial Vision (STSIVA) 2019
We propose constructing effective nonseparable filter banks by combinatorially combining 1D separable filters, yielding computational advantages for CNNs and convolutional sparse coding.
Combinatorial Separable Convolutional Dictionaries
Jorge Quesada, Gustavo Silva, Paul Rodríguez, Brendt Wohlberg
IEEE Symposium on Image, Signal Processing and Artificial Vision (STSIVA) 2019
We propose constructing effective nonseparable filter banks by combinatorially combining 1D separable filters, yielding computational advantages for CNNs and convolutional sparse coding.
2018
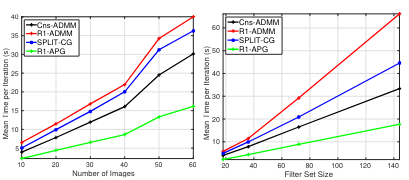
Efficient Separable Filter Estimation Using Rank-1 Convolutional Dictionary Learning
Gustavo Silva, Jorge Quesada, Paul Rodríguez
IEEE International Workshop on Machine Learning for Signal Processing (MLSP) 2018
We introduce a rank-1 constrained method to estimate separable filters for convolutional dictionary learning, improving efficiency while preserving reconstruction quality.
Efficient Separable Filter Estimation Using Rank-1 Convolutional Dictionary Learning
Gustavo Silva, Jorge Quesada, Paul Rodríguez
IEEE International Workshop on Machine Learning for Signal Processing (MLSP) 2018
We introduce a rank-1 constrained method to estimate separable filters for convolutional dictionary learning, improving efficiency while preserving reconstruction quality.
Separable Dictionary Learning for Convolutional Sparse Coding via Split Updates
Jorge Quesada, Paul Rodríguez, Brendt Wohlberg
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2018
We directly learn K separable dictionary filters for convolutional sparse coding via split-update optimization, enabling faster training with separability constraints.
Separable Dictionary Learning for Convolutional Sparse Coding via Split Updates
Jorge Quesada, Paul Rodríguez, Brendt Wohlberg
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2018
We directly learn K separable dictionary filters for convolutional sparse coding via split-update optimization, enabling faster training with separability constraints.
Efficient GPU-based Implementation of the Median Filter Based on a Multi-Pixel-per-Thread Framework
Gabriel Salvador, Juan M. Chau, Jorge Quesada, Cesar Carranza
IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI) 2018
We present a CUDA median-filter design that assigns each thread to multiple output pixels and uses sorting-network selection to achieve strong speedups for large kernels.
Efficient GPU-based Implementation of the Median Filter Based on a Multi-Pixel-per-Thread Framework
Gabriel Salvador, Juan M. Chau, Jorge Quesada, Cesar Carranza
IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI) 2018
We present a CUDA median-filter design that assigns each thread to multiple output pixels and uses sorting-network selection to achieve strong speedups for large kernels.
2017
Fast Convolutional Sparse Coding with Separable Filters
Gustavo Silva, Jorge Quesada, Paul Rodríguez, Brendt Wohlberg
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2017
We develop a computationally efficient convolutional sparse coding algorithm when atoms are separable, substantially reducing complexity while maintaining accuracy.
Fast Convolutional Sparse Coding with Separable Filters
Gustavo Silva, Jorge Quesada, Paul Rodríguez, Brendt Wohlberg
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2017
We develop a computationally efficient convolutional sparse coding algorithm when atoms are separable, substantially reducing complexity while maintaining accuracy.
2016

Automatic Vehicle Counting Method Based on Principal Component Pursuit Background Modeling
Jorge Quesada, Paul Rodríguez
IEEE International Conference on Image Processing (ICIP) 2016
We use principal component pursuit for robust background modeling and motion segmentation, then count vehicles using spatio-temporal cues to handle occlusions in traffic video.
Automatic Vehicle Counting Method Based on Principal Component Pursuit Background Modeling
Jorge Quesada, Paul Rodríguez
IEEE International Conference on Image Processing (ICIP) 2016
We use principal component pursuit for robust background modeling and motion segmentation, then count vehicles using spatio-temporal cues to handle occlusions in traffic video.